【基因助手】2020酷暑更新,加入新的父系和母系树
【基因助手】 https://geneu.xyz
2020.8.18 更新笔记
搜索时,加入新的父系和母系树
---------------------------------我是分割线---------------------------------
2019.12.25 更新笔记
距离上次更新转眼一年过去了,在各大土豪基因公司的补贴中,这一年基因用户迅猛增长,越来越多的用户做了全序测试,父系母系树也茁壮成长,枝繁叶茂,一派欣欣向荣。
虽然国内几家公司都在尝试构建自己的全序树,但不得不说,要想搞好全序树还是靠样本说话,国内公司的优势还是在Y-DNA的O系树高通样本量够多,但对于其他非O系的Y单倍群,和母系单倍群树。国内公司极度缺乏高通样本,基本还是空白,只能借鉴YFull的已有树形,挂上去,这。。显然是本末倒置的。不过对于我们广大基友来说,对于百家争鸣的局面,也只能各取所长。
这次基因助手,新增功能:
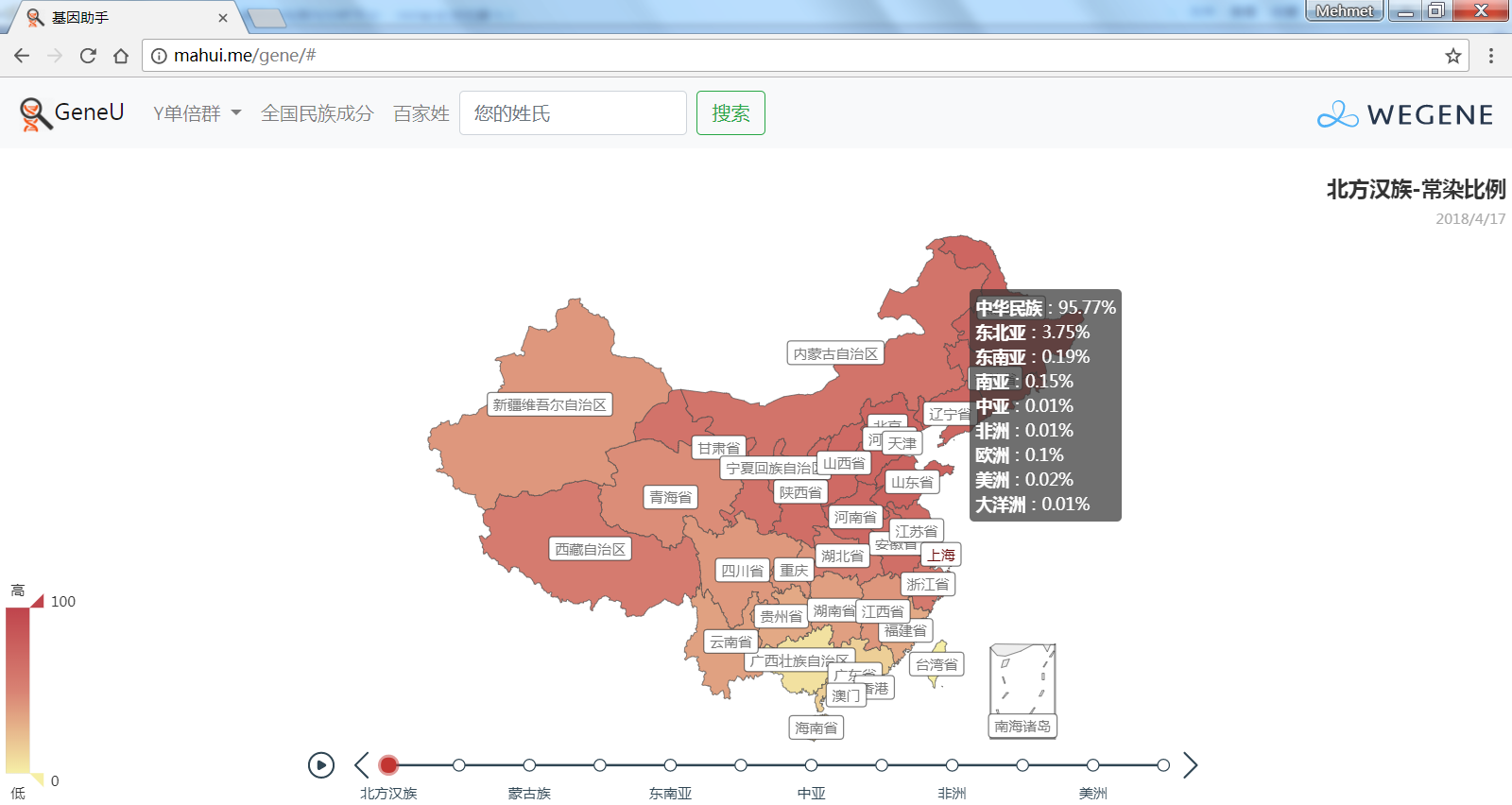
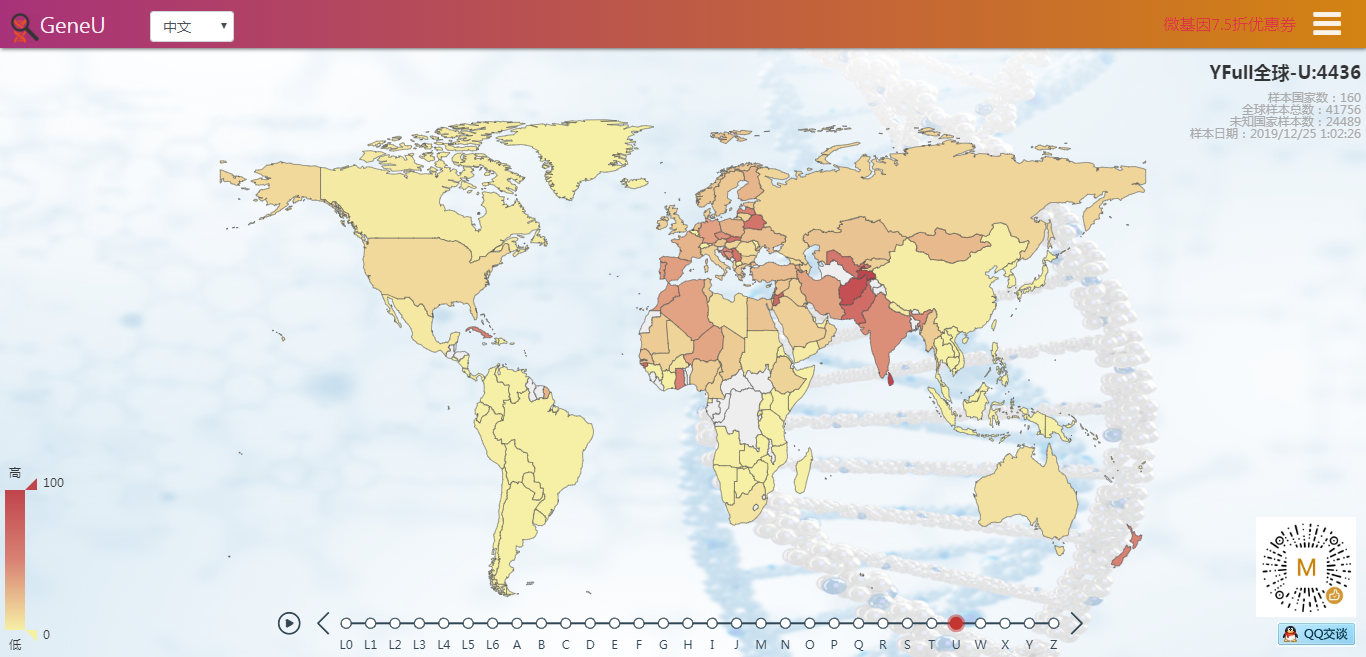
截止到今天,YFull的母系高通样本达到了41756个,其中有24489个是科学样本或匿名样本,未提供样本所在地区。但即使这样,我们仍然能通过这几万个样本,对母系Mt在全球的分布情况一目了然:母系Mt与父系Y类似,非洲的母系多样性仍然是最多的(L0~L6),而其他大洲的母系人群只是走出非洲的L3下游,但时至今日,从L3发展出来的人数已经远远超过了留在非洲的人数。
由于母系Mt的突变率远比父系Y要慢,而且人类社会大多数时候是父系主导,家族通过父姓传承,所以母系不像父系那样容易追踪历史文化,但足够多的母系高通样本量也能给各位基因爱好者带来充分的探索空间。
基因助手将与时俱进,在2020年春节时,再给各位基友带来新年重磅功能,敬请期待!
下面引用大咖王博士关于母系Mt的说明:https://www.wegene.com/question/201
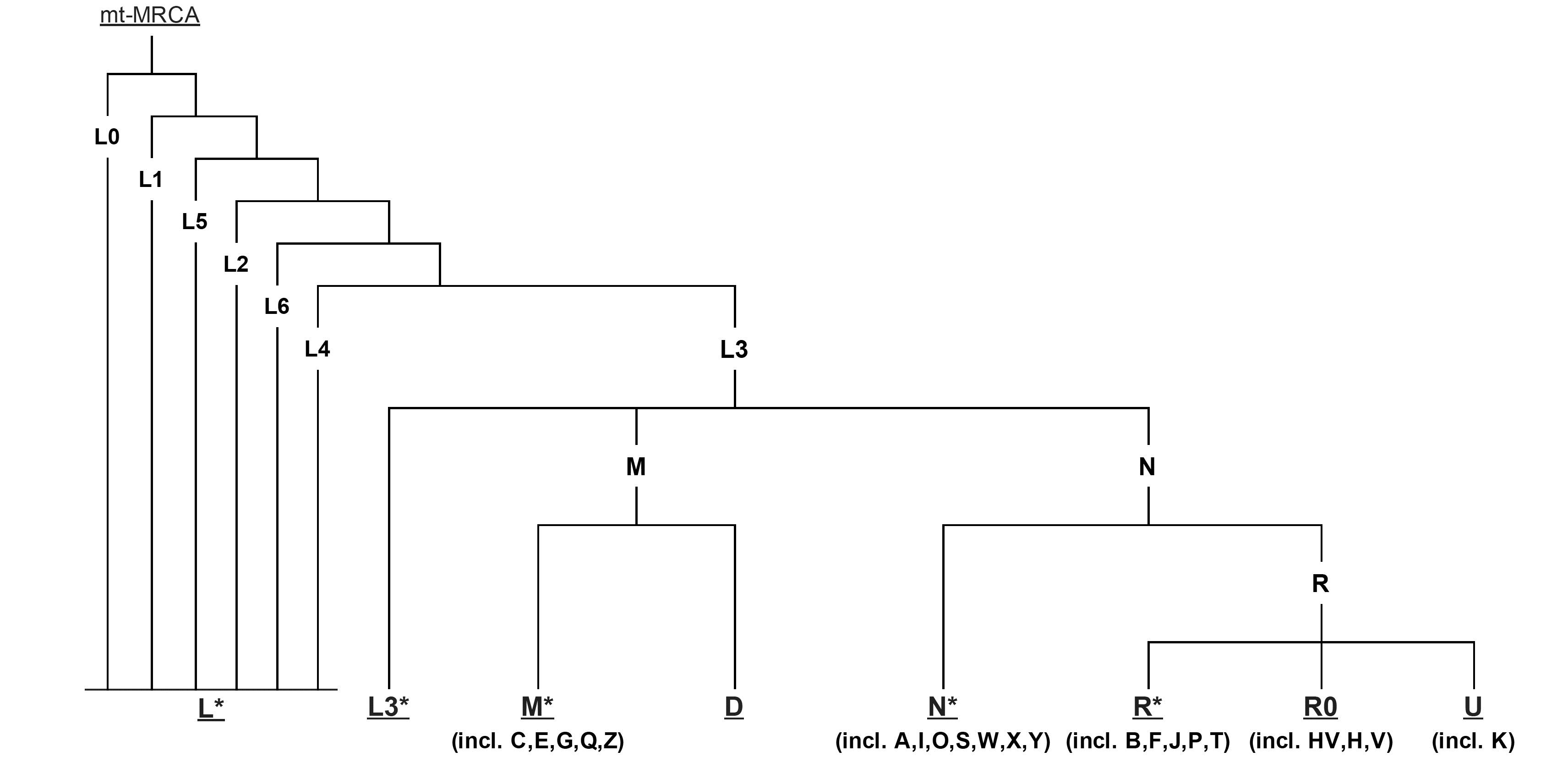
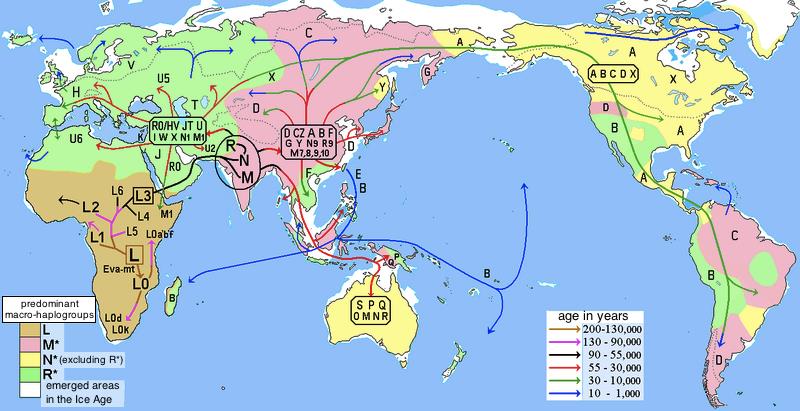
线粒体DNA是严格母系遗传,具有高拷贝数,无重组和高突变率等特性,使它成为反映人群母系进化的理想标记,利用线粒体DNA上的突变,研究者们构建了人类线粒体序列的系统进化树,并定义线粒体单倍型和单倍群,通过世界范围内线粒体单倍群的分布就可以描绘出现代人群母系祖先迁徙的路线。mtDNA的支系分布是很有地域特异性的,例如非洲大陆特异地单倍群 L 比欧亚人群中发现的类型都要古老,L单倍群被分成L0,L1,L2, L3, L4,L5和L6这几支,,其中L3 是欧亚人群中的mtDNA的祖先型。非洲以外的所有mtDNA分为M和N两大超级单倍群,其中N包括了所有欧亚西部特异的谱系H、I、J、K、T、U、V、W 和X,东亚特异的A、B、R9,N9以及大洋州特异的P单倍群也属于N分枝;M单倍群的下游分支有分布在东亚C、D、G、M7、M8、M9等以及在南亚和东南亚常见的M根部支系。美洲土著人群的分析则表明他们大多只属于A、B、C、D这4 种单倍群,很少的个体属于X单倍群。
在东亚北方和南方的mtDNA单倍群分布非常不同,东亚北方主要由A,C,D4,D5, G, M8, M9, N9, Z支系组成,而南方为B4, B5a,F, M7, R9等单倍群组成。
北方谱系中的C、D、G、M8、M9都是M单倍群的下游分枝,M单倍群只存在于东非、南亚、大洋州,东亚和中亚群体中,而在欧亚西部地区几乎完全缺乏。北亚主要的mtDNA单倍群是C, D, A, B4, G及N9等一些在东亚也高频出现的单倍群,另外混有一些末次盛冰期之后从欧亚西部流入的以H、J、U为主的支系。东亚来源的北亚单倍群有M下的 C, D, G, M3, M7-M11, M13和Z单倍群, N支系下的 A, N9a 和 Y,以及R支系下的 B, F, R9, R11。单倍群C和D在东北亚非常多,在某些群体中所占比例超过50%,甚至能达80%以上。通过对单倍群C和D的样本进行全测序,发现C和D的祖先支系早在3-5万年之前就已经在东亚诞生,并且随即进入南西伯利亚,而大多数的北亚C和D支系都是在末次冰盛期之后才扩张。虽然北亚的主流单倍群是C和D,而单倍群A也在某些群体中高频分布,比如占到了楚克其人的73%。北亚的单倍群B的支系主要是B4和B5,这两个支系分布在偏南的朝鲜和蒙古地区。mtDNA单倍群A在藏族中占到了相当高的比例,平均能达到10%-14%,同时在门巴族(23.5%)和珞巴族(15%)中的频率更高。单倍群D所占比例比A还要高,能达到10%-20%,在珞巴中甚至高达30%。单倍群C在西藏群体中也能占到5%左右。青藏高原藏族中的单倍群A、C、D极可能是由1-2万年前从东亚北方向南进入高原的人群带入的。
而在南方,壮侗和南岛语系同时具有高频率的M7,南亚语系的F单倍型频率也比其它语系高出许多。壮侗群体中,频率最高的单倍群是B4a, F1a, M7b1, B5a, M7b*, M*, R9a, R9b, 这些单倍群的频率总和占到了约一半。苗瑶族群与壮侗族群相似,单倍群B5a, B4a, M*,M7b*, C, B4b1, M7b1, F1a, B4*, R9b也能占到一半,而南亚群体中,频率较高的有F1a, M*, D*, F1b, N*, C, M7b*, M7b1, F1a1a, 前三种占到50.8%,与壮侗和苗瑶略有不同。单倍群B, M7, F, R的总频率在台湾原住民中能占到70%,在壮侗中也达到了66.4%,比苗瑶的58.9%和南亚的48.9%更高,而越往北的类群这一数值就越小,例如占汉族40.8%, 占藏缅族群的37.5%, 而仅占到阿尔泰族群的16.3%,由此可见,B, M7, F, R这四类单倍群是可以代表中国南方的特征单倍群。







---------------------------------我是分割线---------------------------------
2018.12.28 新增功能:
1. 全新UI,更美观、秀色可餐。。
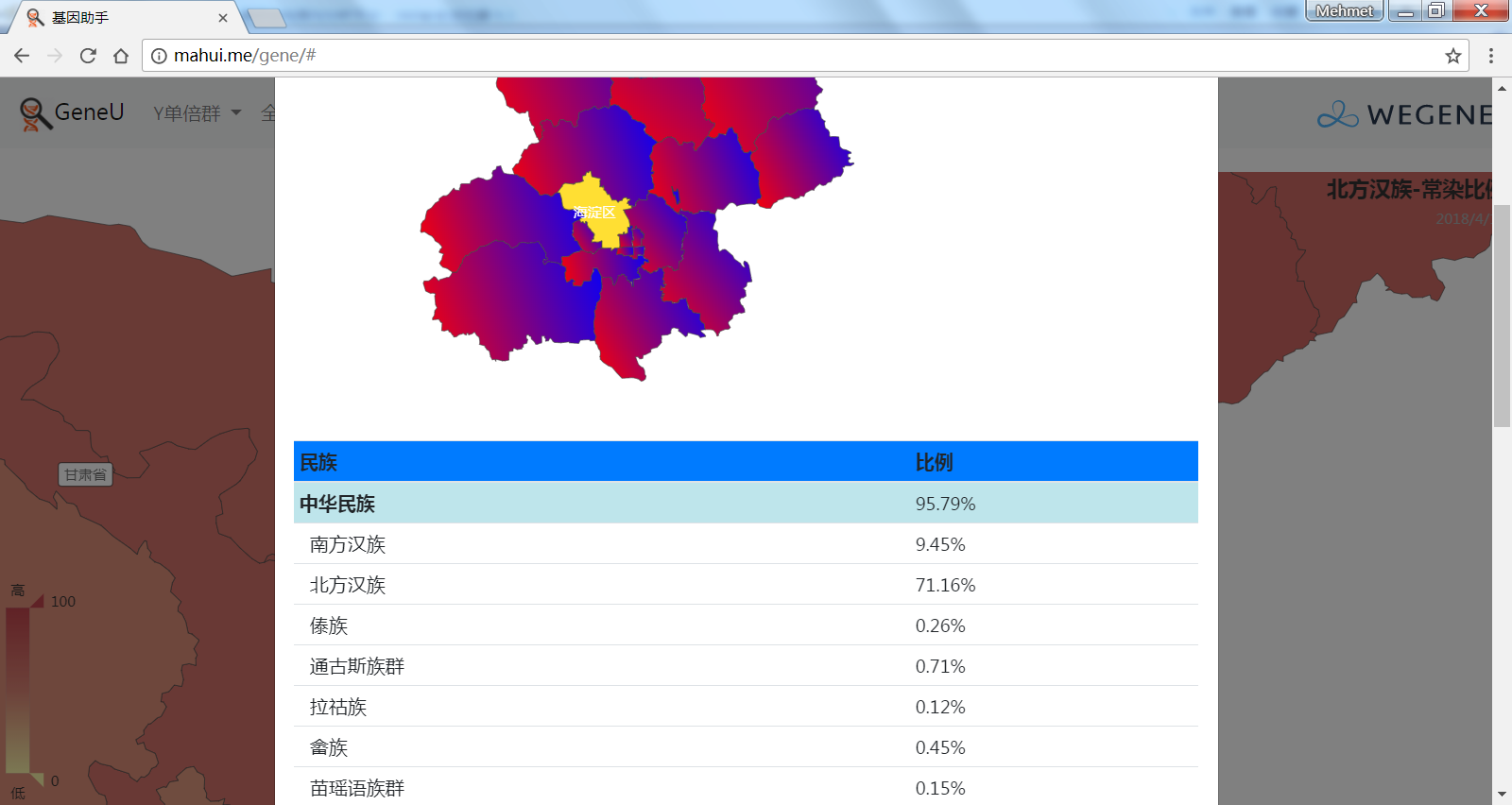
2.(需要登录)民.族统计,各民族的父系Y分布、母系mt分布、祖源分布。
3.(需要登录)中国父系Y地域分布,按各省份、地市统计父系Y分布。
4.(需要登录)中国母系mt地域分布,按各省份、地市统计母系mt分布。
5.(需要登录)中国母系mt顶层单倍群组成。





首先你需要:
1,参加微基因的“姓氏嗍源”
https://www.wegene.com/surname/result/
2,参加微基因的“祖源相似性”
https://www.wegene.com/ancestry/similarity/details/
这样就可以在【基因助手】看到你的数据了!
以上所有数据信息,都与微基因同步实时更新,SNP引用最新版的ISOGG 2018.5数据,共祖时间TMRCA与YFull同步更新,微基因用户点击右上角LOGO登录后,可看到自己账号下的基因信息,包括父系Y和母系mt,祖源成分和同Y用户的分布,可以私信联系。
感谢微基因的大力支持!如果需要更多功能,欢迎大家留言提建议给我。







2020.8.18 更新笔记
搜索时,加入新的父系和母系树
---------------------------------我是分割线---------------------------------
2019.12.25 更新笔记
距离上次更新转眼一年过去了,在各大土豪基因公司的补贴中,这一年基因用户迅猛增长,越来越多的用户做了全序测试,父系母系树也茁壮成长,枝繁叶茂,一派欣欣向荣。
虽然国内几家公司都在尝试构建自己的全序树,但不得不说,要想搞好全序树还是靠样本说话,国内公司的优势还是在Y-DNA的O系树高通样本量够多,但对于其他非O系的Y单倍群,和母系单倍群树。国内公司极度缺乏高通样本,基本还是空白,只能借鉴YFull的已有树形,挂上去,这。。显然是本末倒置的。不过对于我们广大基友来说,对于百家争鸣的局面,也只能各取所长。
这次基因助手,新增功能:
- 实时同步 YFull 的母系全球数据,在世界地图上展示,可看到每个国家的母系分布比例和所有的母系样本。
- 可搜索某个YFull母系单倍群,比如输入母系I1c1a,在世界地图上展示此单倍群下的所有样本,如果你有YFull帐号,还可以给非科学和匿名样本发私信。
截止到今天,YFull的母系高通样本达到了41756个,其中有24489个是科学样本或匿名样本,未提供样本所在地区。但即使这样,我们仍然能通过这几万个样本,对母系Mt在全球的分布情况一目了然:母系Mt与父系Y类似,非洲的母系多样性仍然是最多的(L0~L6),而其他大洲的母系人群只是走出非洲的L3下游,但时至今日,从L3发展出来的人数已经远远超过了留在非洲的人数。
由于母系Mt的突变率远比父系Y要慢,而且人类社会大多数时候是父系主导,家族通过父姓传承,所以母系不像父系那样容易追踪历史文化,但足够多的母系高通样本量也能给各位基因爱好者带来充分的探索空间。
基因助手将与时俱进,在2020年春节时,再给各位基友带来新年重磅功能,敬请期待!
下面引用大咖王博士关于母系Mt的说明:https://www.wegene.com/question/201
线粒体DNA是严格母系遗传,具有高拷贝数,无重组和高突变率等特性,使它成为反映人群母系进化的理想标记,利用线粒体DNA上的突变,研究者们构建了人类线粒体序列的系统进化树,并定义线粒体单倍型和单倍群,通过世界范围内线粒体单倍群的分布就可以描绘出现代人群母系祖先迁徙的路线。mtDNA的支系分布是很有地域特异性的,例如非洲大陆特异地单倍群 L 比欧亚人群中发现的类型都要古老,L单倍群被分成L0,L1,L2, L3, L4,L5和L6这几支,,其中L3 是欧亚人群中的mtDNA的祖先型。非洲以外的所有mtDNA分为M和N两大超级单倍群,其中N包括了所有欧亚西部特异的谱系H、I、J、K、T、U、V、W 和X,东亚特异的A、B、R9,N9以及大洋州特异的P单倍群也属于N分枝;M单倍群的下游分支有分布在东亚C、D、G、M7、M8、M9等以及在南亚和东南亚常见的M根部支系。美洲土著人群的分析则表明他们大多只属于A、B、C、D这4 种单倍群,很少的个体属于X单倍群。
在东亚北方和南方的mtDNA单倍群分布非常不同,东亚北方主要由A,C,D4,D5, G, M8, M9, N9, Z支系组成,而南方为B4, B5a,F, M7, R9等单倍群组成。
北方谱系中的C、D、G、M8、M9都是M单倍群的下游分枝,M单倍群只存在于东非、南亚、大洋州,东亚和中亚群体中,而在欧亚西部地区几乎完全缺乏。北亚主要的mtDNA单倍群是C, D, A, B4, G及N9等一些在东亚也高频出现的单倍群,另外混有一些末次盛冰期之后从欧亚西部流入的以H、J、U为主的支系。东亚来源的北亚单倍群有M下的 C, D, G, M3, M7-M11, M13和Z单倍群, N支系下的 A, N9a 和 Y,以及R支系下的 B, F, R9, R11。单倍群C和D在东北亚非常多,在某些群体中所占比例超过50%,甚至能达80%以上。通过对单倍群C和D的样本进行全测序,发现C和D的祖先支系早在3-5万年之前就已经在东亚诞生,并且随即进入南西伯利亚,而大多数的北亚C和D支系都是在末次冰盛期之后才扩张。虽然北亚的主流单倍群是C和D,而单倍群A也在某些群体中高频分布,比如占到了楚克其人的73%。北亚的单倍群B的支系主要是B4和B5,这两个支系分布在偏南的朝鲜和蒙古地区。mtDNA单倍群A在藏族中占到了相当高的比例,平均能达到10%-14%,同时在门巴族(23.5%)和珞巴族(15%)中的频率更高。单倍群D所占比例比A还要高,能达到10%-20%,在珞巴中甚至高达30%。单倍群C在西藏群体中也能占到5%左右。青藏高原藏族中的单倍群A、C、D极可能是由1-2万年前从东亚北方向南进入高原的人群带入的。
而在南方,壮侗和南岛语系同时具有高频率的M7,南亚语系的F单倍型频率也比其它语系高出许多。壮侗群体中,频率最高的单倍群是B4a, F1a, M7b1, B5a, M7b*, M*, R9a, R9b, 这些单倍群的频率总和占到了约一半。苗瑶族群与壮侗族群相似,单倍群B5a, B4a, M*,M7b*, C, B4b1, M7b1, F1a, B4*, R9b也能占到一半,而南亚群体中,频率较高的有F1a, M*, D*, F1b, N*, C, M7b*, M7b1, F1a1a, 前三种占到50.8%,与壮侗和苗瑶略有不同。单倍群B, M7, F, R的总频率在台湾原住民中能占到70%,在壮侗中也达到了66.4%,比苗瑶的58.9%和南亚的48.9%更高,而越往北的类群这一数值就越小,例如占汉族40.8%, 占藏缅族群的37.5%, 而仅占到阿尔泰族群的16.3%,由此可见,B, M7, F, R这四类单倍群是可以代表中国南方的特征单倍群。
---------------------------------我是分割线---------------------------------
2018.12.28 新增功能:
1. 全新UI,更美观、秀色可餐。。
2.(需要登录)民.族统计,各民族的父系Y分布、母系mt分布、祖源分布。
3.(需要登录)中国父系Y地域分布,按各省份、地市统计父系Y分布。
4.(需要登录)中国母系mt地域分布,按各省份、地市统计母系mt分布。
5.(需要登录)中国母系mt顶层单倍群组成。
首先你需要:
1,参加微基因的“姓氏嗍源”
https://www.wegene.com/surname/result/
2,参加微基因的“祖源相似性”
https://www.wegene.com/ancestry/similarity/details/
这样就可以在【基因助手】看到你的数据了!
- 中国各省市的祖源成分(常染匹配),以中国地图展现微基因支持的民族成分平均比例,比如中国北方和南方汉族和少数民族、国外民族在各省市的比例。
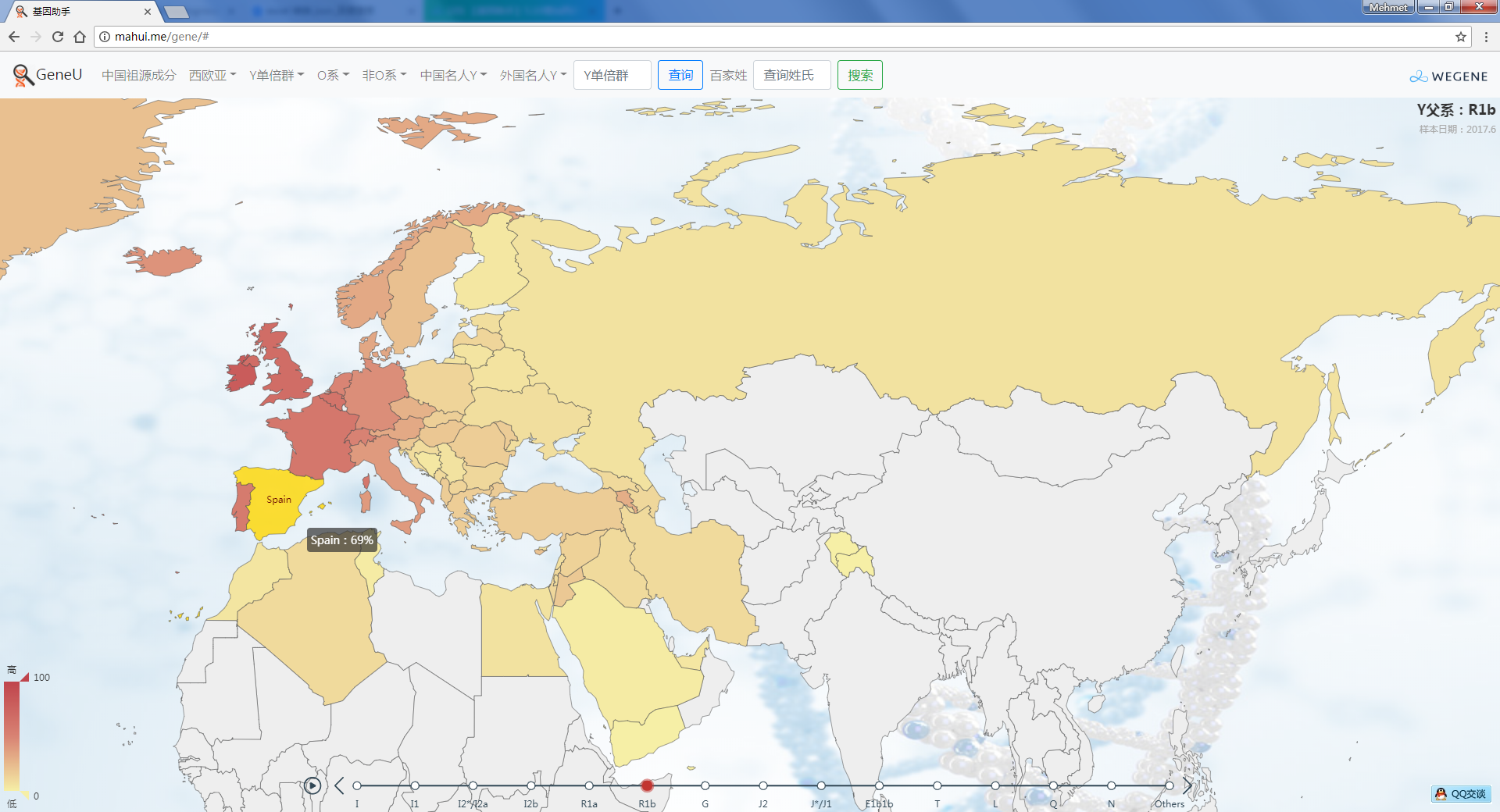
- YFull全球实时统计,以世界地图展现YFull数据,与YFull同步更新,目前涵盖约140个国家、14000个全球样本。
- 饼图展示顶层Y单倍群,包括各顶层单倍群和下游单倍群的人数和比例,不管你是中国最多的O系,还是少数类型 C, D, N, Q, R, J, I, G...在这里都可以看到自己单倍群的人数和比例,以及此单倍群下的所有姓氏。
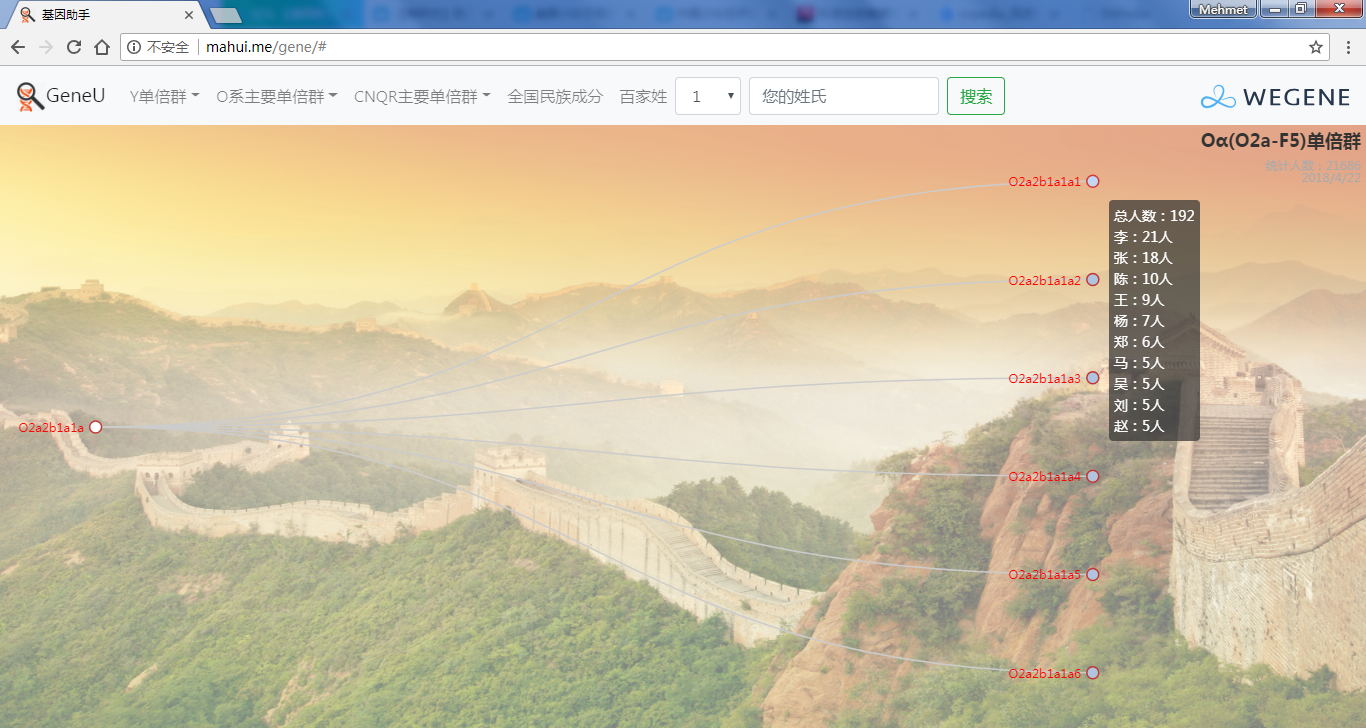
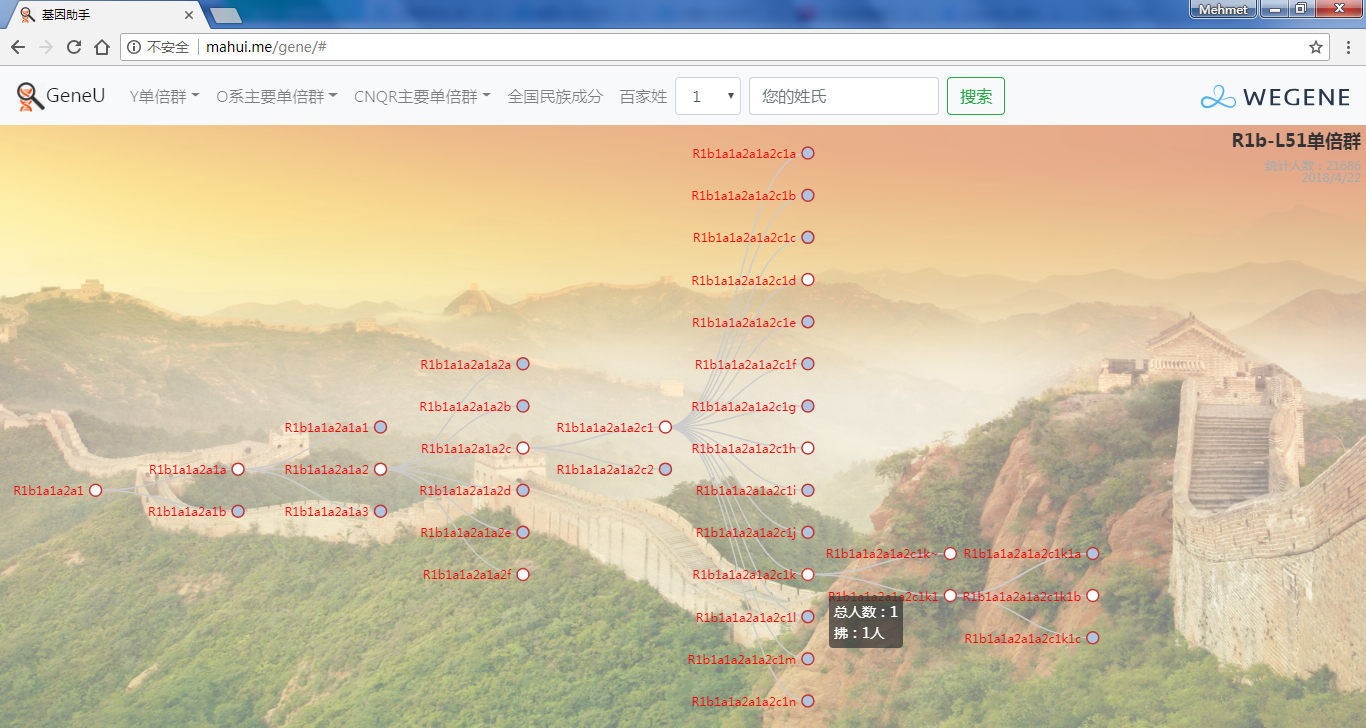
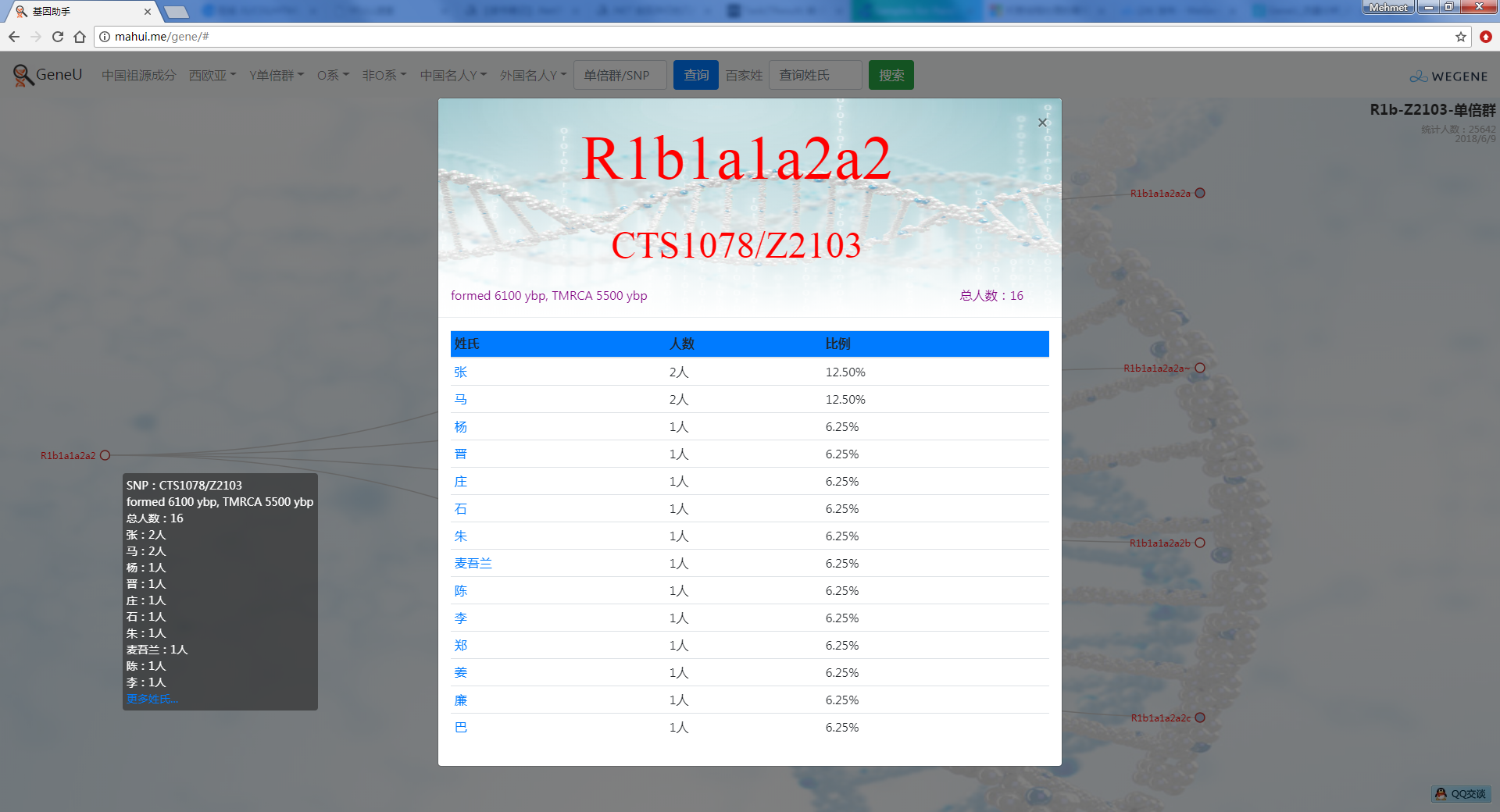
- 树形图展示欧亚常见的Y单倍群及所有下游分支,每个Y单倍群的形成年代和共祖时间TMRCA(与YFull同步更新),比如Oα(O2a-F5)、Oβ(O2a-F46)、Oγ(O2a-F11)、C2南支北支、N南支北支、R1a-Z283(东欧常见类型)、R1a-Z93(印度-雅利安类型)、R1b-M73(中亚常见类型)、R1b-L51(西欧常见类型)、R1b-Z2103(高加索、土耳其、巴尔干常见类型)等。
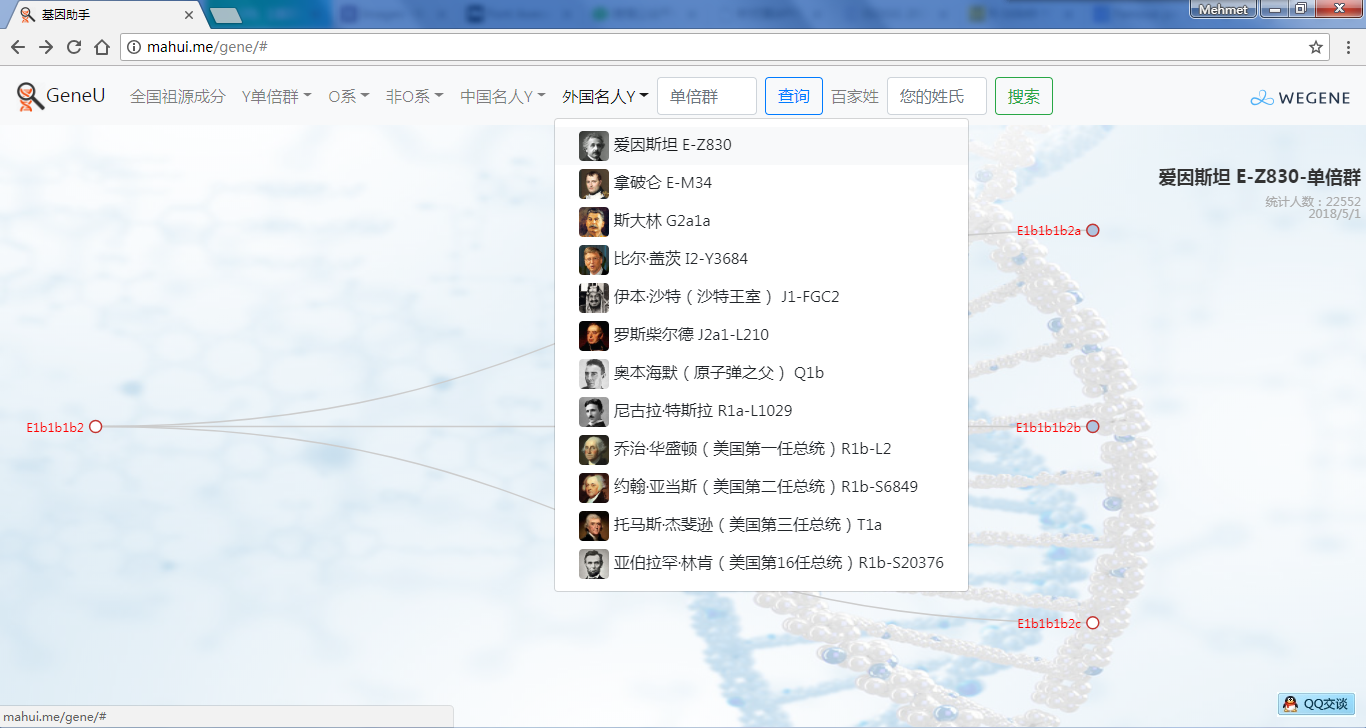
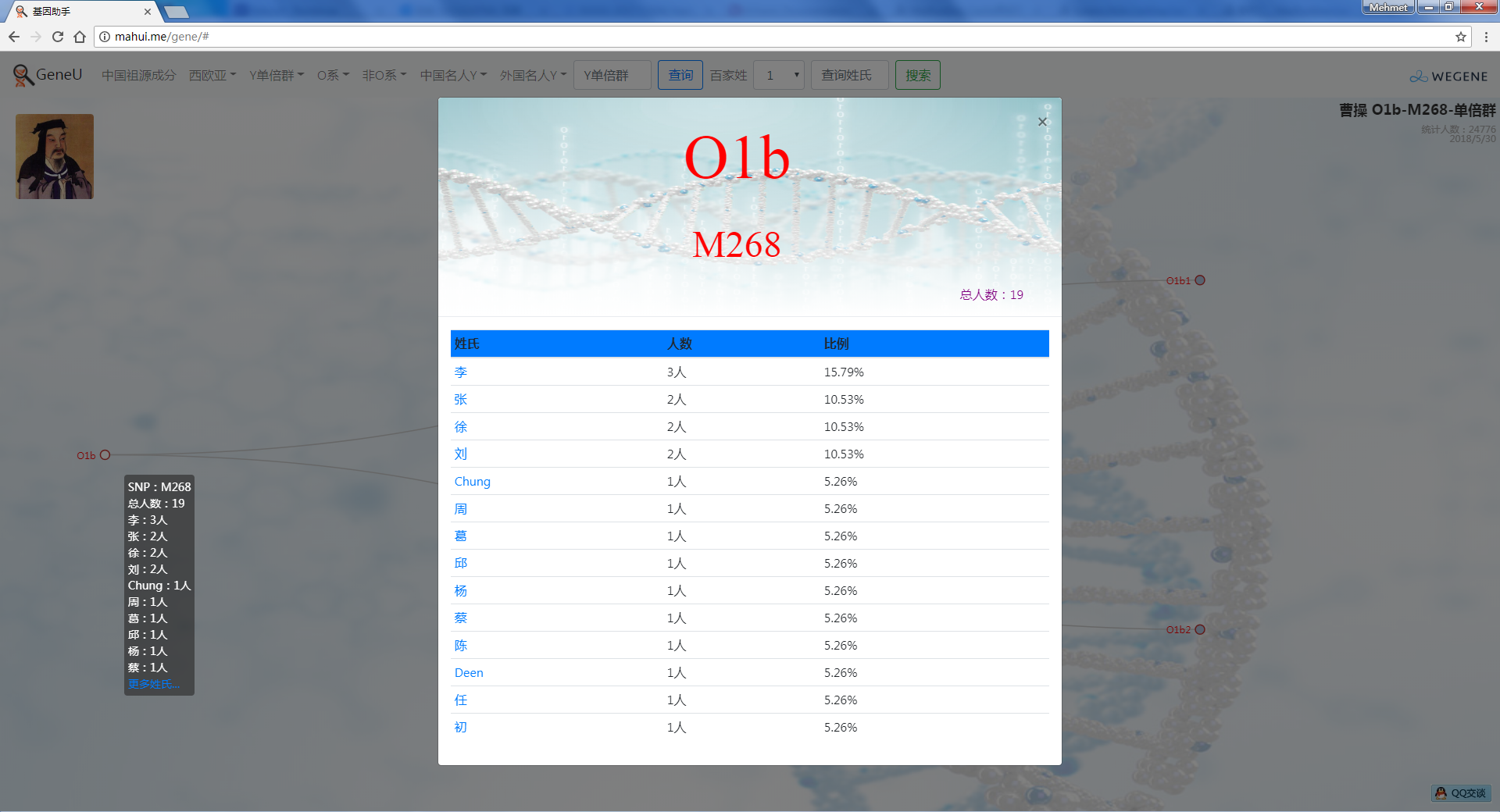
- 中外名人Y,提供了业界考古论证的中外历史名人家族单倍群Y,可看到自己是不是这个名人家族的:)
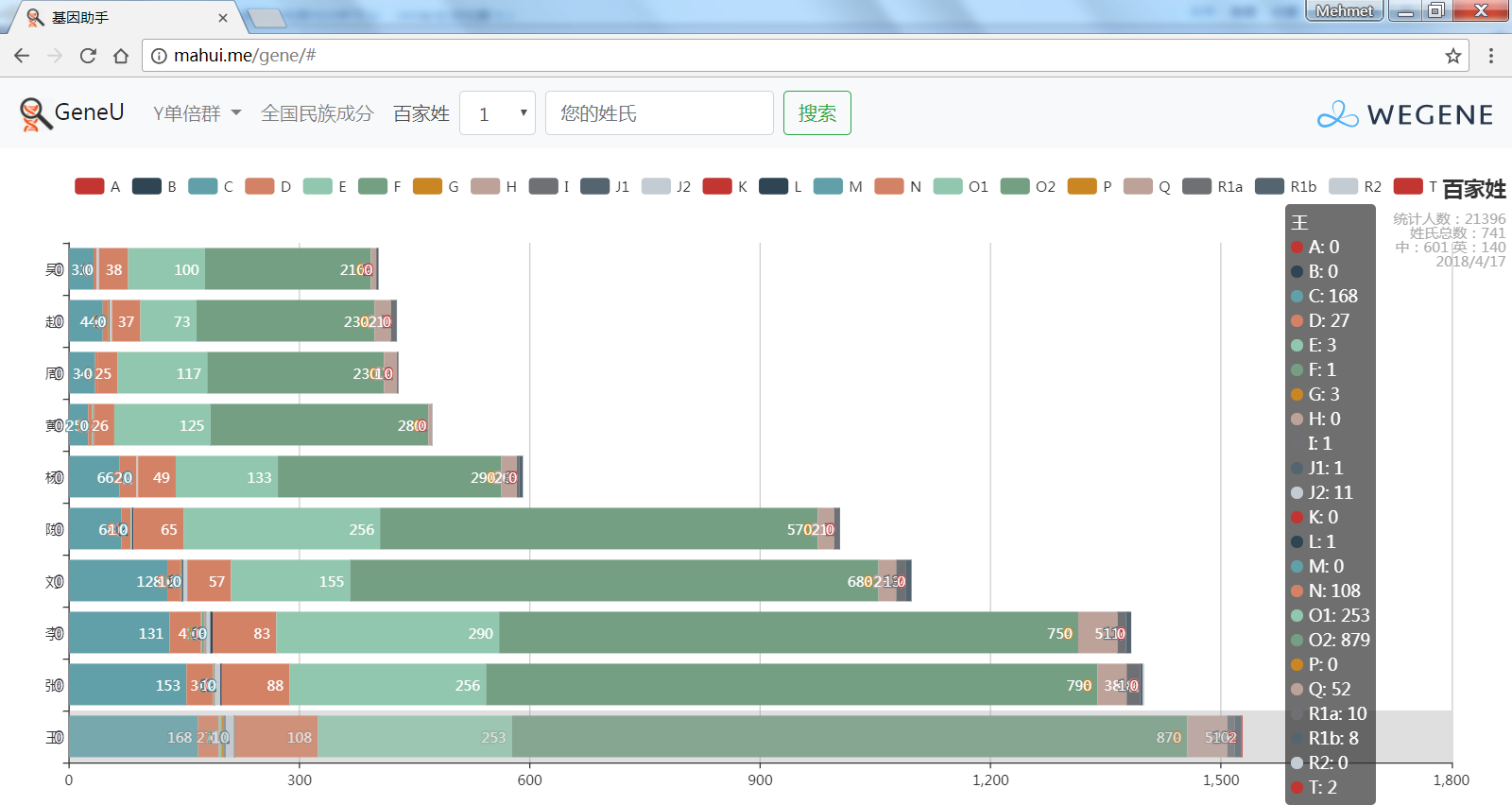
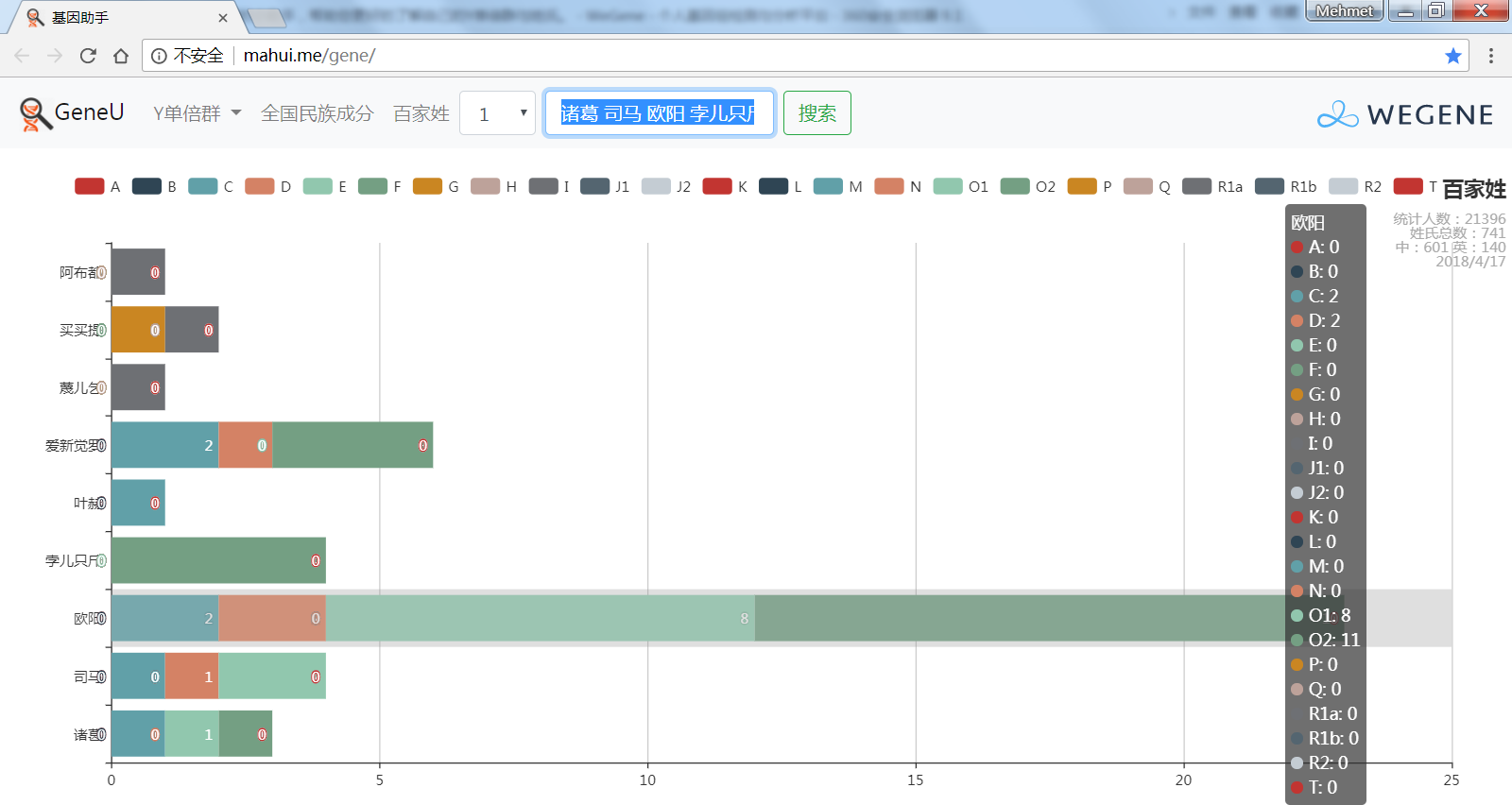
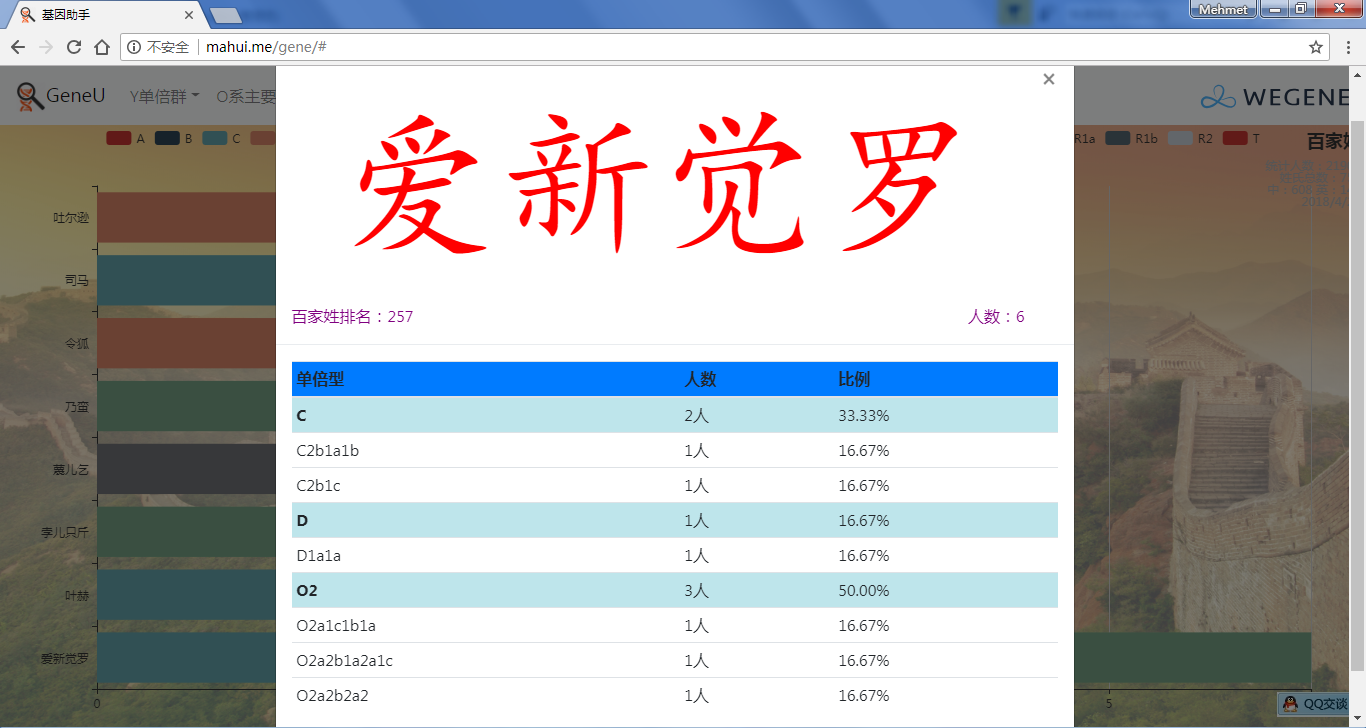
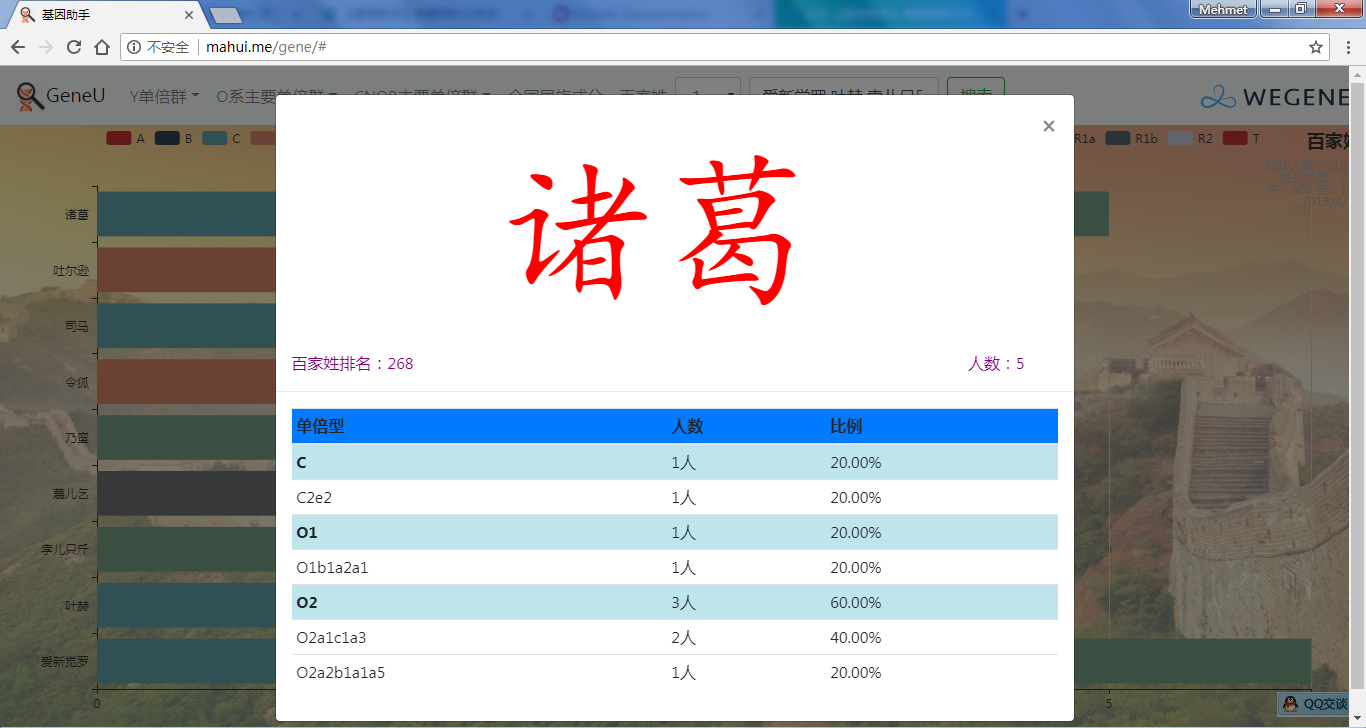
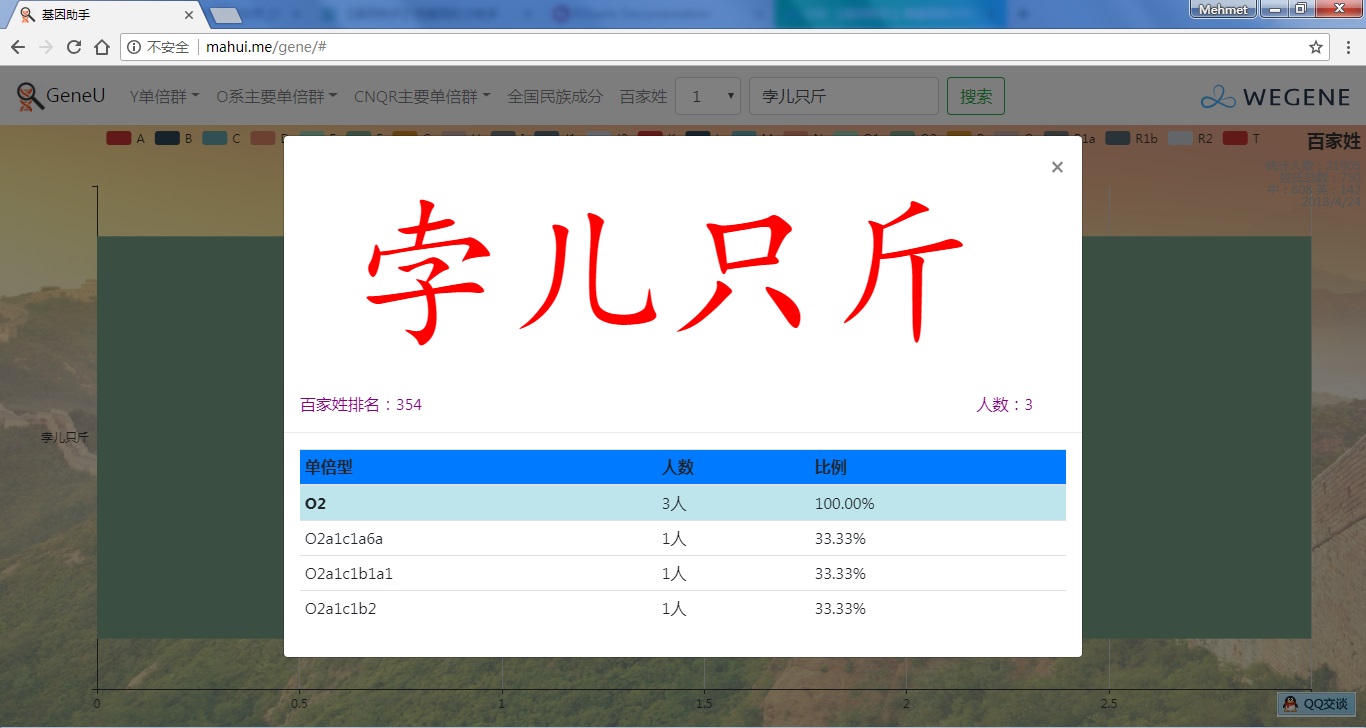
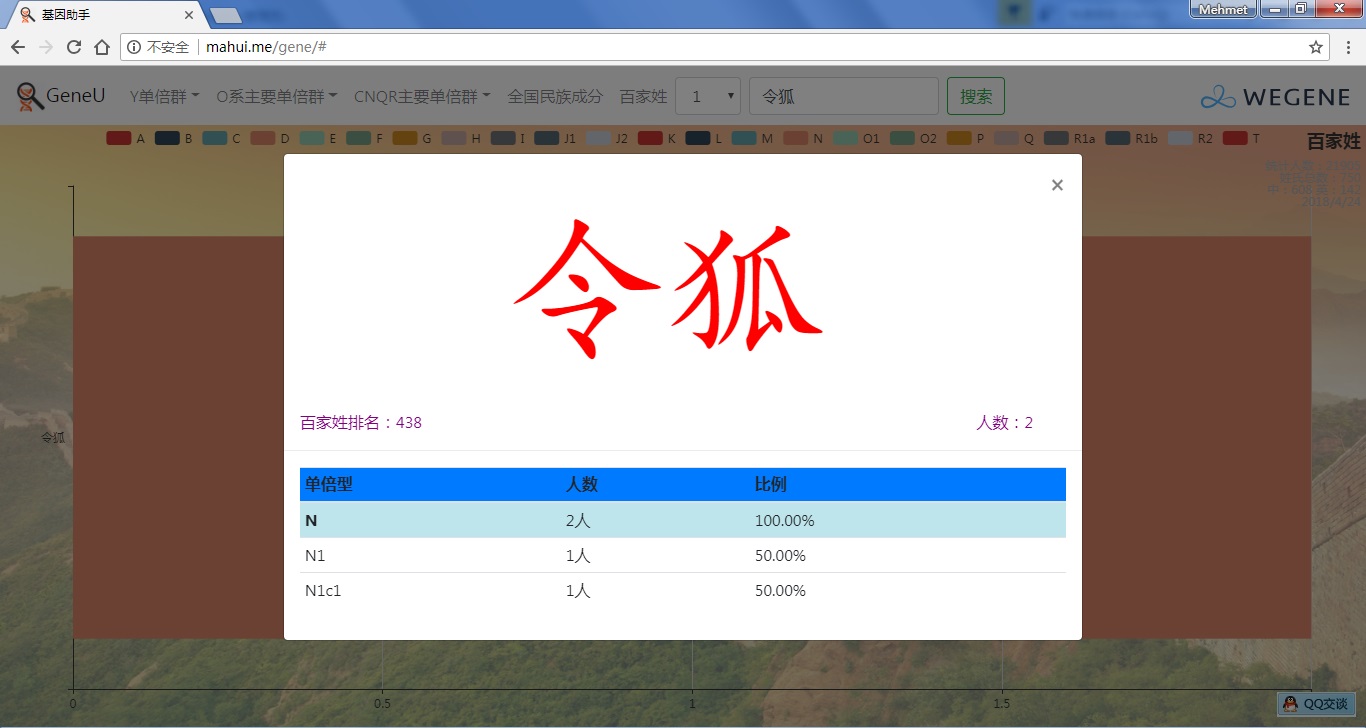
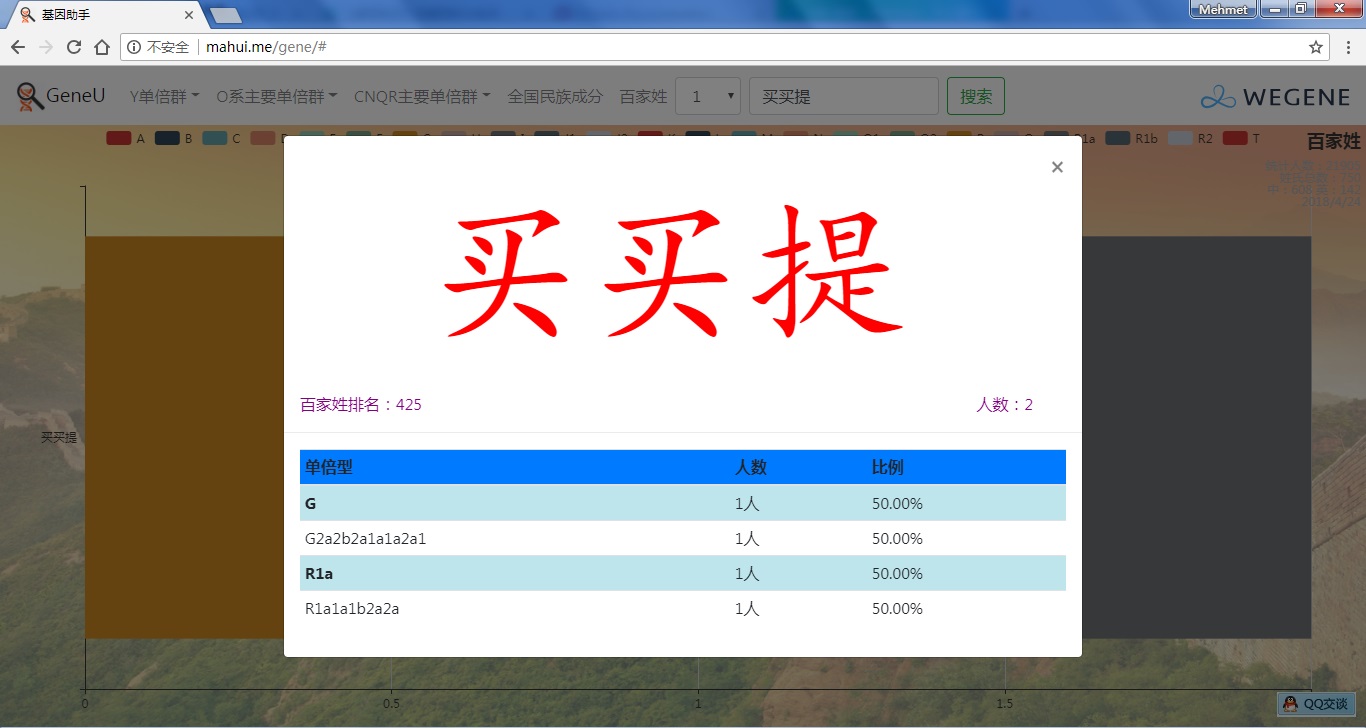
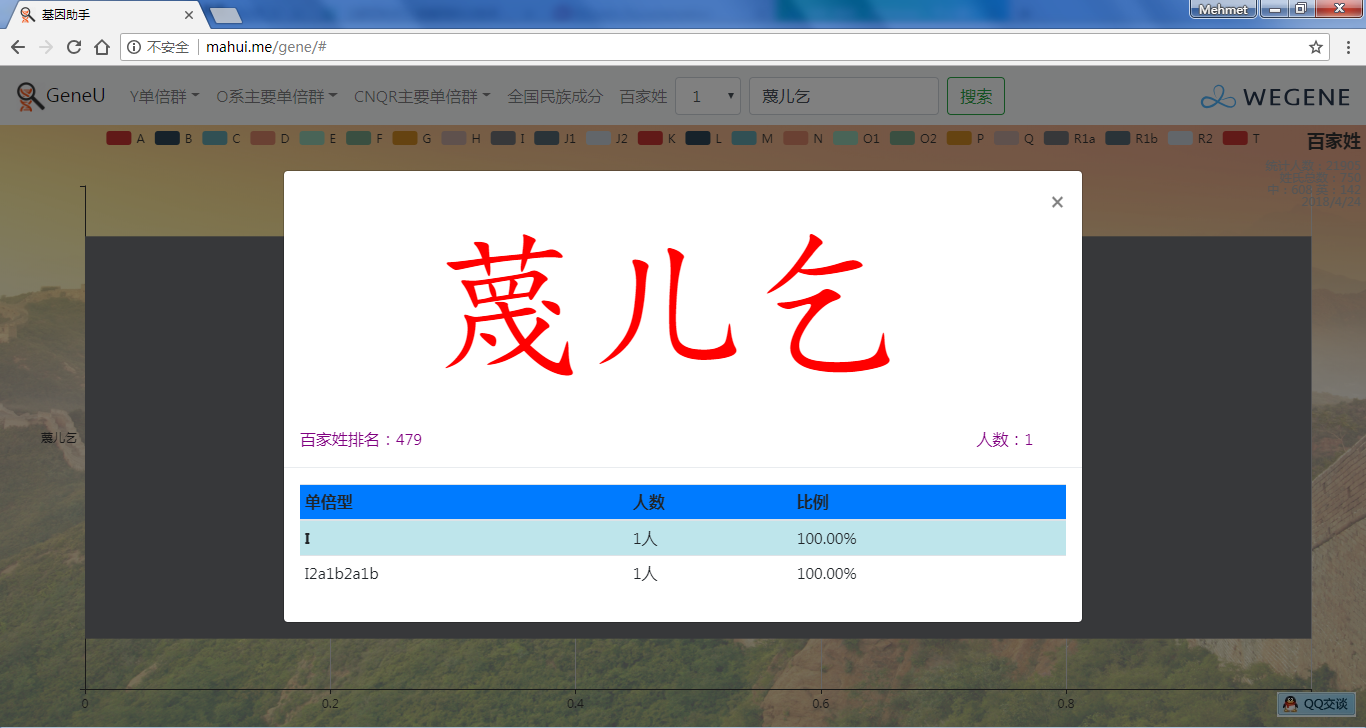
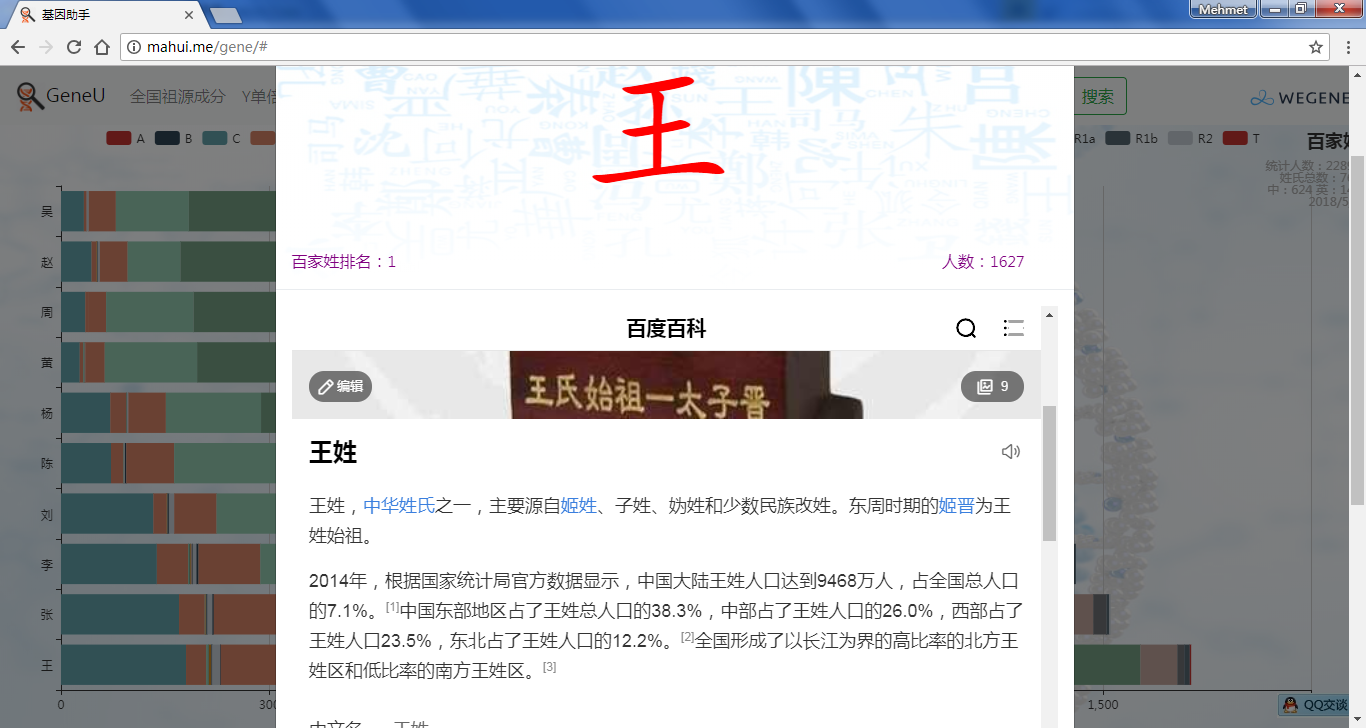
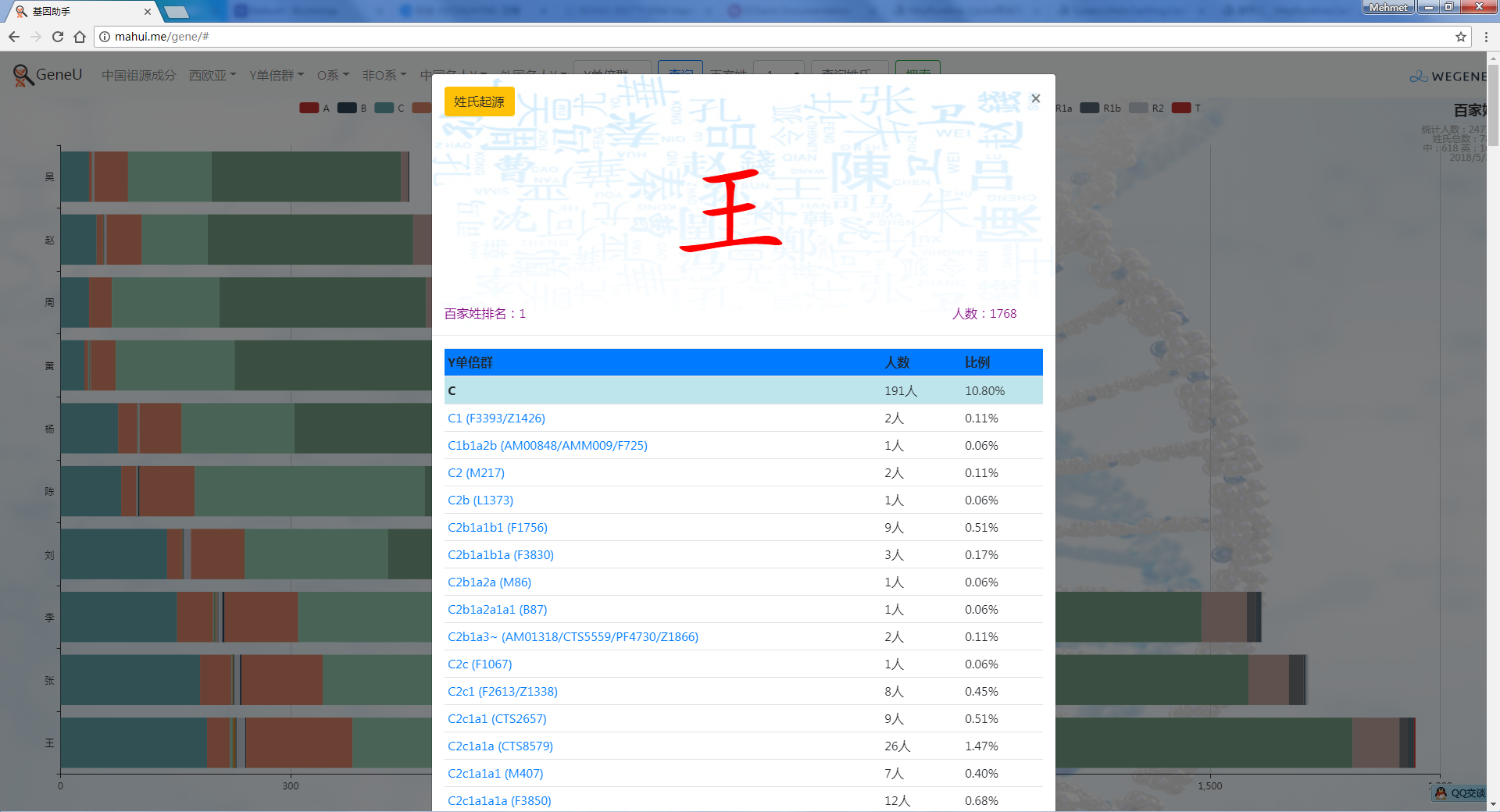
- 百家姓,按人数排行的姓氏列表,以及每个姓氏的Y单倍群构成、姓氏起源,中英文分别引用百度姓氏和Wiki姓氏,目前已有700多个姓氏,包括中文姓氏、日文姓氏和英文姓氏,很多中文姓氏都是稀有姓氏,包括诸葛、司马、慕容、令狐、公孙、爱新觉罗、孛儿只斤、叶赫、乃蛮、蔑儿乞等拥有悠久历史的中华民族姓氏。看来很多朋友是来寻根问祖的哦,大家也可以看到英国小网红“拂菻坊”@fulinfang 的姓氏和单倍群,他的Y单倍体是典型的西欧类型 R1b1a1a2a1
- 使用姓氏识别算法,对微基因用户的原始姓氏数据进行整理,智能识别中文、日文、英文姓氏、繁体字、复姓、少数民族常见姓氏,确保姓氏统计结果更精确。
- 由于数据量较大,所以第一次访问菜单中任何单倍群信息时,将在用户浏览器里缓存数据,只要不刷新页面,访问菜单里其他单倍群信息都将从浏览器缓存里获取数据,提高了访问速度,如果想查看最新数据,只需要按F5刷新页面重新获取数据即可。
以上所有数据信息,都与微基因同步实时更新,SNP引用最新版的ISOGG 2018.5数据,共祖时间TMRCA与YFull同步更新,微基因用户点击右上角LOGO登录后,可看到自己账号下的基因信息,包括父系Y和母系mt,祖源成分和同Y用户的分布,可以私信联系。
感谢微基因的大力支持!如果需要更多功能,欢迎大家留言提建议给我。


118 个回复
赞同来自: Mehmet
赞同来自: Mehmet
赞同来自: Mehmet
赞同来自: Mehmet
赞同来自:
http://mahui.me/gene/?HG=C2
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
2018.4.29
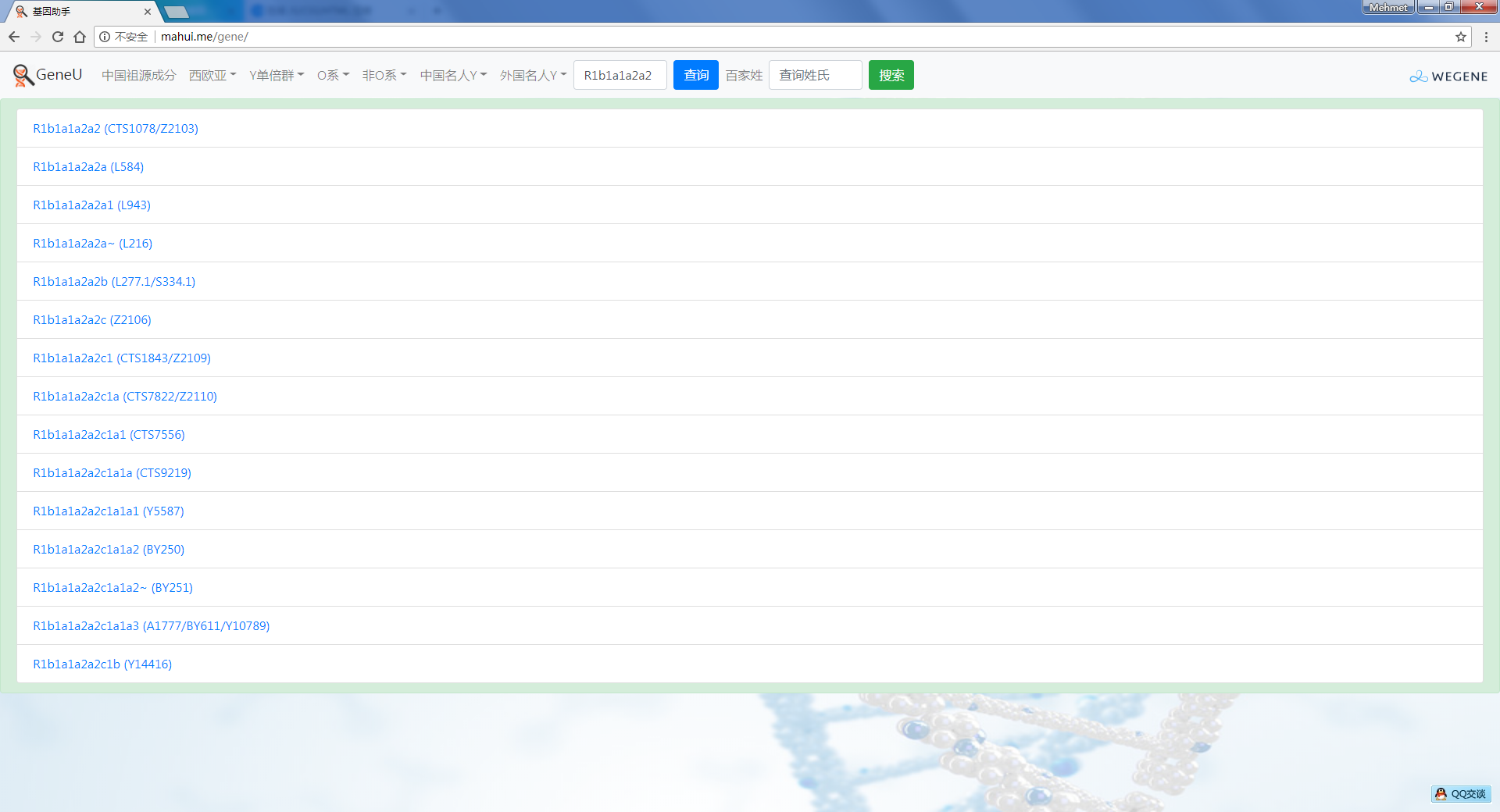
在菜单栏里增加了直接查询Y单倍群功能,可查询任意单倍群,比如R1b1a1a2,以树形图展示。
赞同来自:
赞同来自:
2018.5.2
在百家姓里加入了姓氏起源说明,可切换浏览姓氏下的Y单倍群和姓氏起源。
赞同来自:
基因助手目前只提供Y染色体的查询,姓氏查询,常染查询,所有数据都和微基因保持同步更新。
女性如果希望知道自己家族的Y染色体,可以让父亲或兄弟来测试,就知道了。
这里有个王博士的Y染色体科普:
https://www.wegene.com/question/200
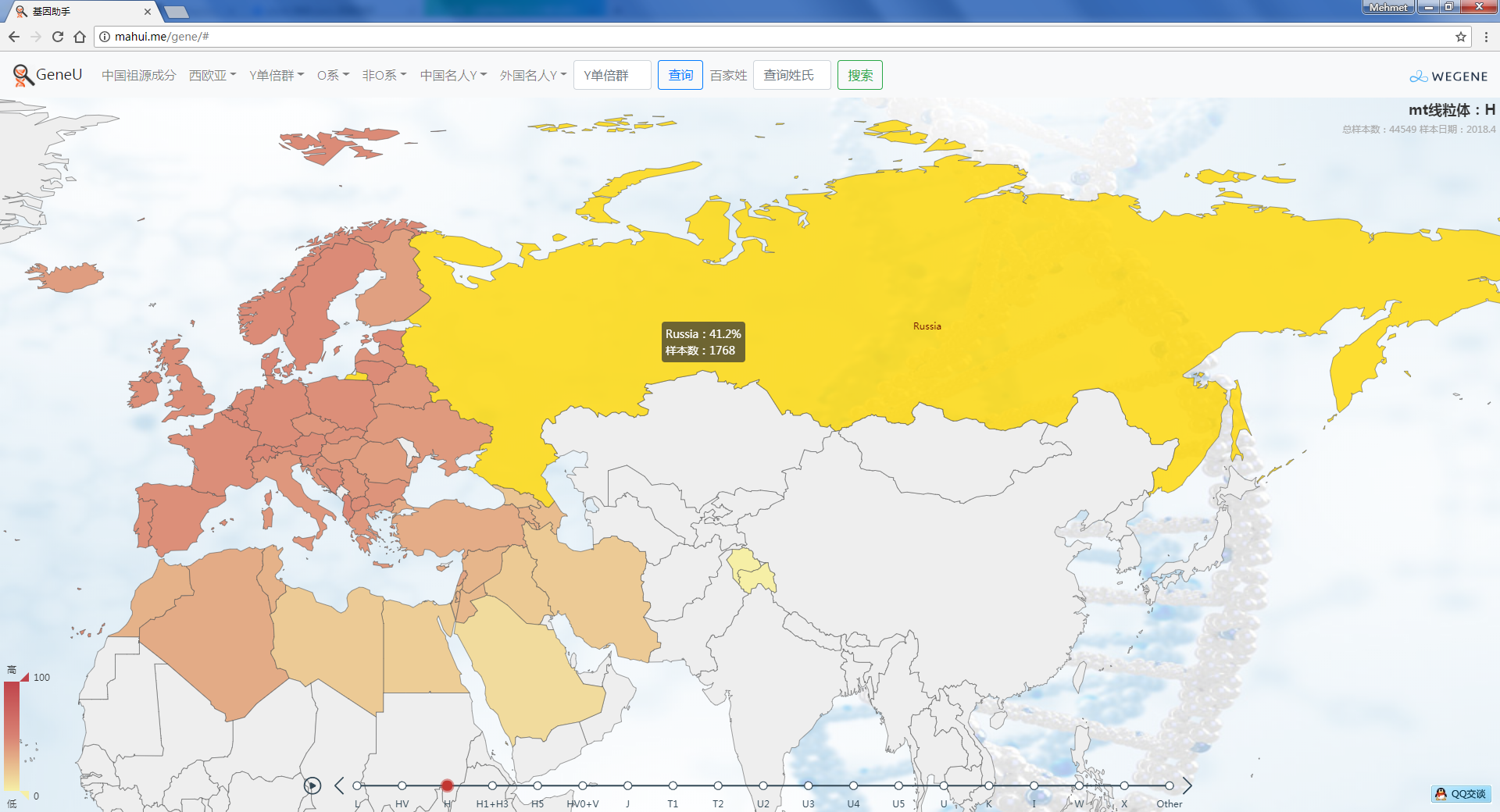
关于mt线粒体在欧洲的分布:
http://mahui.me/gene/?wemt
https://www.eupedia.com/europe/european_mtdna_haplogroups_frequency.shtml
赞同来自:
赞同来自:
赞同来自:
2018.5.12
根据Eupedia资料,增加西欧亚的父系Y和母系mt单倍群统计,以世界地图展现,目前父系Y数据截止2017.6,母系mt数据截止2018.4,样本总数44549,以后随eupedia实时更新。
赞同来自:
赞同来自:
2018.5.14
百家姓增加识别日本最常见1000个姓氏,参考:
https://baike.baidu.com/item/%E6%97%A5%E6%9C%AC%E5%A7%93%E6%B0%8F/530940?fr=aladdin
@Akiossan
赞同来自:
赞同来自:
2018.5.31
可直接查询单倍群或SNP,比如输入R1b1a1a2a2,或者Z2103,点击查询,可显示多个查询结果,点击结果中的单倍群,即可显示单倍群树。
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
赞同来自:
1. 全新UI,更美观、秀色可餐。。
2.(需要登录)民族统计,各民.族的父系Y分布、母系mt分布、平均祖源分布。
3.(需要登录)父系Y地域分布,按各省份、地市统计父系Y分布,可查询任何父系Y分支的全国分布。
4.(需要登录)母系mt地域分布,按各省份、地市统计母系mt分布。
5.(需要登录)母系mt顶层单倍群组成。
赞同来自:
赞同来自:
赞同来自:
我在基因助手上民族-Y-Mt-常染模块看到所有新O1(O1-F265)大支所有民族的统计加起来男性样本数达到了 75人,且和我同支的在基因助手分布图里数了是5个,而基因助手上Y-地域图上显示只有统计2名男性样本,而我在基因助手上民族-Y-Mt-常染模块看到所有民族的统计加起来男性样本数更达到了414人,怎么会出现民族-Y-Mt-常染模块和Y-地域图上实际统计和Y-地域图上显示统计人数不一样的情况呢?
赞同来自:
赞同来自:
要回复问题请先登录或注册